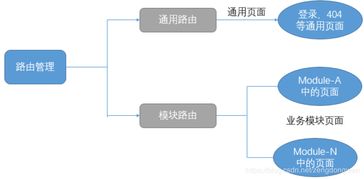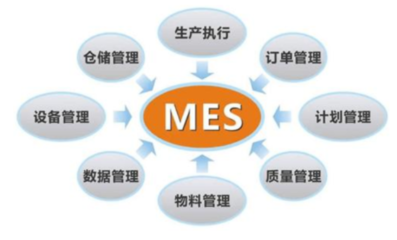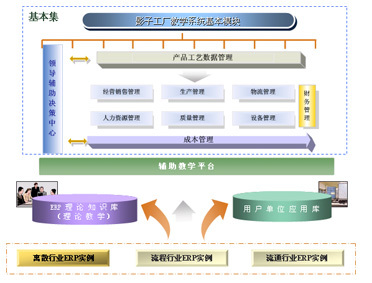
影子工廠(Shadow Factory)是一種數據處理服務模式,其名稱源于其在生產系統之外并行運行,像一個“影子”一樣復制真實環境。它主要用于數據處理、系統測試、分析和優化,而不會影響實際業務運營。以下從定義、主要功能、應用場景和優勢進行詳細介紹。
影子工廠通過復制生產環境的數據和流程,在隔離的系統中模擬真實業務操作。例如,在軟件開發中,它可以用于測試新功能或數據遷移策略,確保變更不會導致生產系統故障。數據處理服務包括數據清洗、轉換、分析和建模,影子工廠可以安全地處理敏感數據,而無需直接訪問生產數據庫。
影子工廠在數據處理服務中的核心功能包括:性能測試、風險管理和數據模擬。例如,金融機構可能用它來模擬市場波動對數據的影響,以評估風險管理策略;電商平臺則可能用它來測試新推薦算法,而不干擾用戶的實際體驗。通過這種方式,企業可以提前發現潛在問題,提高系統可靠性和數據處理效率。
在實際應用中,影子工廠常用于大數據分析、AI模型訓練和系統升級。一個典型例子是,一家公司可能在生產系統外運行影子工廠來處理歷史數據,訓練機器學習模型,從而優化客戶服務。這減少了生產環境中的資源競爭,并確保了數據安全合規。
影子工廠的優勢在于提升靈活性、降低風險和降低成本。它允許團隊在不影響實時業務的情況下進行實驗和創新,同時通過模擬真實場景來避免數據泄露或系統崩潰。影子工廠作為一種高效的數據處理服務,正成為現代企業數字化轉型的重要工具,幫助實現更安全、更智能的運營管理。